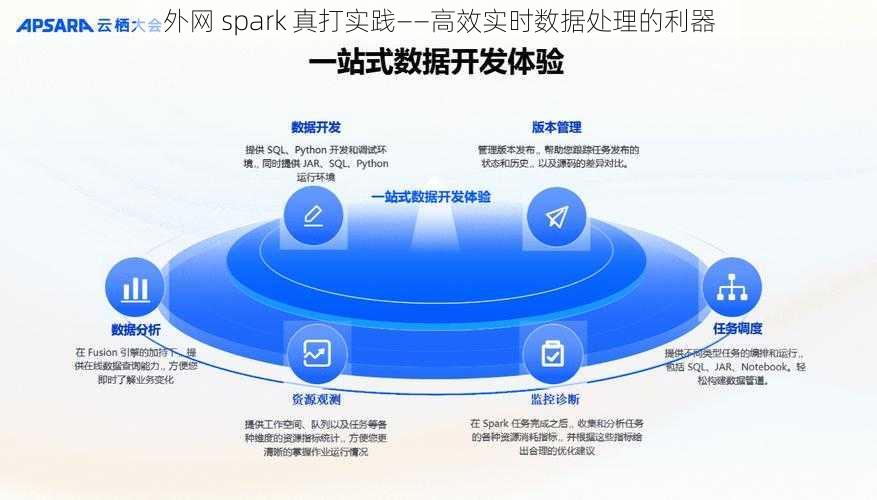
外网 spark 真打实践——高效实时数据处理的利器
在当今数字化时代,数据的实时处理和分析变得至关重要。无论是在线零售、社交媒体还是金融市场,企业都需要能够快速处理海量数据并做出明智决策。外网 Spark 作为一款强大的分布式计算框架,为高效实时数据处理提供了利器。将深入探讨外网 Spark 的实践应用,帮助读者了解其在数据处理领域的优势和潜力。
什么是外网 Spark?
外网 Spark 是一种基于内存计算的大数据处理框架,它具有高效、灵活和可扩展的特点。相比于传统的批处理框架,Spark 能够在更短的时间内处理大规模数据集,并提供了丰富的数据分析和机器学习功能。
外网 Spark 的优势
1. 快速处理速度:Spark 利用内存计算技术,能够大大提高数据处理的效率,使得实时数据分析成为可能。
2. 强大的数据分析能力:除了基本的数据处理功能外,Spark 还支持机器学习、图计算和流处理等高级分析任务。
3. 分布式架构:Spark 可以运行在分布式集群上,通过并行处理和数据分布,能够处理海量数据。
4. 良好的兼容性:Spark 可以与多种数据源和数据存储进行集成,提供了更广泛的应用场景。
外网 Spark 的应用场景
1. 实时数据分析:用于监控网站流量、交易数据等实时信息,及时发现异常和趋势。
2. 数据挖掘和机器学习:处理和分析大规模数据集,发现潜在的模式和关系。
3. 流式数据处理:实时处理源源不断的数据,如传感器数据、网络流量等。
4. 数据仓库迁移:将传统的数据仓库迁移到 Spark 平台上,提高数据处理的效率和灵活性。
外网 Spark 的实践案例
1. 电商网站用户行为分析:通过 Spark 对用户的浏览、购买等行为数据进行实时分析,为个性化推荐和营销策略提供支持。
2. 金融风险预警:利用 Spark 对市场数据进行实时监测和分析,及时发现风险信号。
3. 物联网数据分析:处理物联网设备产生的海量数据,实现设备状态监测和故障预测。
外网 Spark 的技术实现
1. 弹性分布式数据集(RDD):Spark 的核心数据结构,是一种只读的、分区的数据集合。
2. DAG 调度器:用于管理 Spark 作业的执行流程,将作业分解为多个阶段,并进行调度和执行。
3. 内存管理:Spark 通过合理的内存管理机制,提高数据的缓存和重用效率。
4. 集群资源管理:Spark 可以与集群管理器(如 YARN)进行集成,实现资源的高效分配和管理。
外网 Spark 的未来发展趋势
1. 与人工智能的融合:结合 Spark 的强大数据分析能力和人工智能技术,实现更智能的实时决策。
2. 实时流式计算的进一步发展:不断提升 Spark 在实时流式数据处理方面的性能和功能。
3. 跨平台和多语言支持:增加对更多操作系统和编程语言的支持,方便开发者使用。
4. 与其他大数据技术的集成:与 Hadoop、Kafka 等其他大数据技术更好地融合,提供更全面的数据处理解决方案。
外网 Spark 作为高效实时数据处理的利器,已经在各个领域得到了广泛的应用。读者可以了解到 Spark 的优势、应用场景和技术实现。在大数据时代,掌握外网 Spark 的技术和实践经验对于企业和数据分析师来说至关重要。未来,随着技术的不断发展,Spark 有望继续发挥重要作用,为数据处理带来更高的效率和价值。
建议:
1. 深入学习 Spark 的原理和实践,通过在线课程、书籍和开源项目来提升自己的技能。
2. 结合实际业务需求,探索 Spark 在不同领域的应用案例,将其应用到实际项目中。
3. 关注 Spark 的最新发展动态,参与相关的技术社区和研讨会,与同行交流和分享经验。
4. 在使用 Spark 进行数据处理时,注重数据质量和安全性,确保数据的合法性和合规性。
以上文章仅供参考,你可以根据自己的需求进行修改和完善。